
The question “how much does it cost to train an AI model?” is deceptively simple, and the answer spans five orders of magnitude. Fine-tuning a small language model on a curated dataset can cost less than $50. Pre-training a frontier-scale foundation model from scratch can exceed $100 million. The AI training cost for your specific project depends on a complex interplay of model architecture, dataset size, GPU selection, cloud provider choice, and engineering optimization.
This guide provides a comprehensive, data-driven budget breakdown for every category of AI training workload in 2026 — from hobbyist fine-tuning to enterprise pre-training. We cover raw GPU compute costs, storage requirements, network overhead, and the often-overlooked engineering labor costs that can dwarf your cloud bill. Whether you are a startup founder planning your first training run or an ML engineering lead presenting a compute budget to your board, this analysis will help you build accurate cost projections.
- Fine-tuning a 7B model with LoRA costs $20-100 on a specialized GPU cloud. Full-weight fine-tuning the same model costs $500-2,000.
- Pre-training a 7B model from scratch on 1T tokens costs approximately $15,000-30,000 on H100 instances.
- Pre-training a 70B model requires $500,000-1,500,000 in compute, depending on GPU selection and provider.
- Engineering labor and data preparation typically add 2-5x on top of raw compute costs for enterprise projects.
The Cost Hierarchy: From Fine-Tuning to Pre-Training
AI training exists on a spectrum of computational intensity. Understanding where your project falls on this spectrum is the first step in building an accurate budget.
The AI Compute Threshold Report
We analyzed pricing from 150+ GPU cloud providers to find the exact threshold where an AI startup's OpenAI API bill eclipses the cost of a dedicated H100 cluster.
Read the Full ReportTier 1: Parameter-Efficient Fine-Tuning (LoRA/QLoRA)
Parameter-Efficient Fine-Tuning (PEFT) methods like LoRA (Low-Rank Adaptation) have revolutionized the economics of model customization. Instead of updating all model weights, LoRA freezes the pre-trained model and injects small trainable matrices into each transformer layer. This reduces the number of trainable parameters by 99%+, which dramatically lowers both VRAM requirements and training time.
For a practical example: fine-tuning Meta’s Llama 3 8B model on a dataset of 50,000 instruction-response pairs using LoRA requires approximately 6-12 GPU-hours on a single A100 80GB GPU. At $2.09/hr on Lambda Labs, the compute cost is approximately $13-25. QLoRA (quantized LoRA) can reduce this further by running on a single RTX 4090 (24GB) at $0.39/hr on RunPod, bringing the total to under $10.
However, LoRA has limitations. The fine-tuned model inherits the base model’s knowledge distribution, and LoRA cannot fundamentally change the model’s core capabilities. If you need to inject substantial new domain knowledge or significantly alter the model’s behavior, you may need full fine-tuning or continued pre-training.
Tier 2: Full-Weight Fine-Tuning
Full fine-tuning updates every parameter in the model, allowing deeper customization but requiring significantly more compute. For a 7B parameter model, full fine-tuning on 500,000 examples requires approximately 200-400 GPU-hours on A100 80GB instances. At $2.09/hr, that translates to $420-840 in pure compute cost.
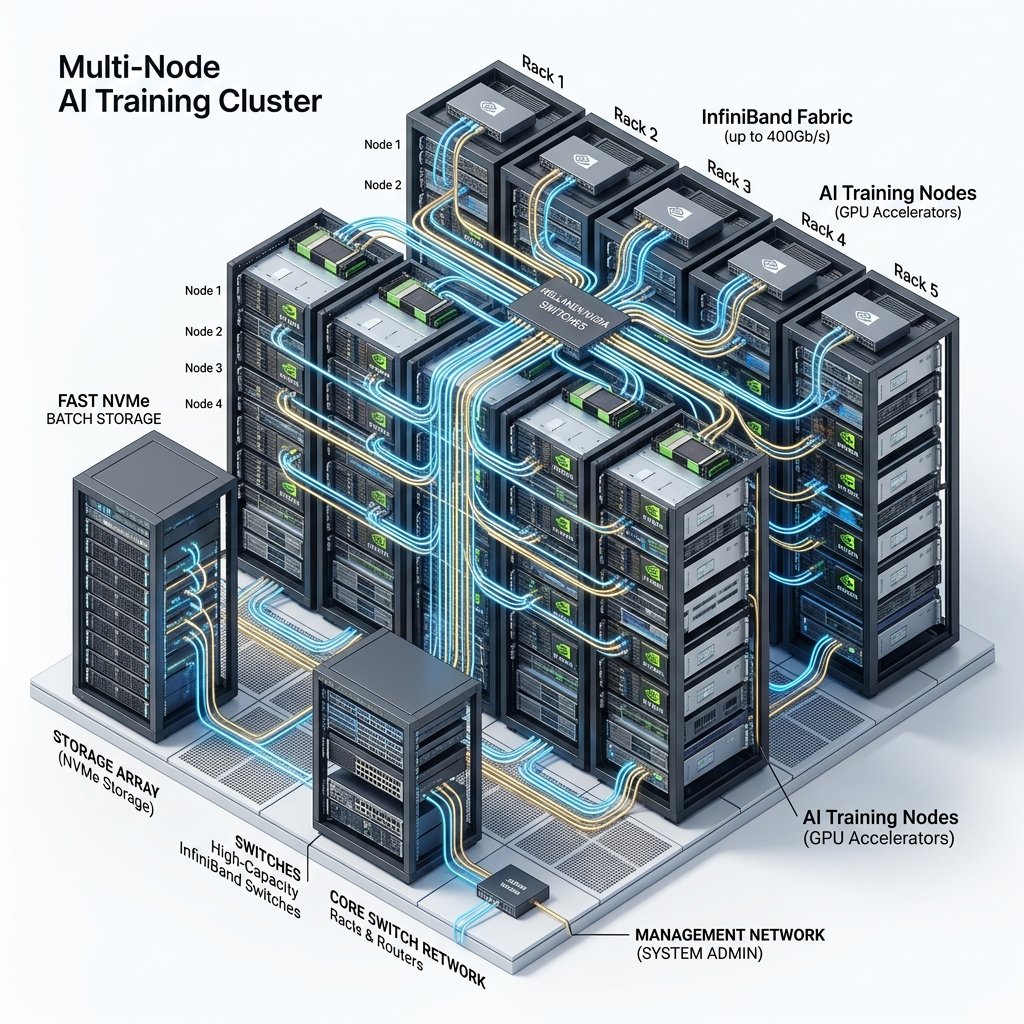
For a 70B parameter model, full fine-tuning becomes a multi-node operation requiring 8-16 A100 80GB GPUs working in parallel with gradient sharding (FSDP or DeepSpeed ZeRO Stage 3). A typical run of 100,000 examples takes approximately 500-1,000 GPU-hours, costing $1,050-2,090 on A100s or $1,745-3,490 on H100s. The H100 is faster but not necessarily cheaper for full fine-tuning of models under 30B parameters.
Tier 3: Continued Pre-Training
Continued pre-training takes an existing base model and trains it on a large corpus of new domain-specific data (typically 10B-100B tokens). This is the preferred method for building domain-specific models — for example, creating a medical LLM by continuing pre-training on PubMed and clinical trial data. The cost scales linearly with token count and model size. For a 7B model, continued pre-training on 50B tokens requires approximately 3,000-5,000 H100 GPU-hours, costing $10,500-17,450.
Tier 4: Pre-Training from Scratch
Pre-training a model from random initialization is the most expensive category of AI training. The compute requirements are governed by the Chinchilla scaling laws, which suggest that optimal training requires approximately 20 tokens per parameter. For a 7B model, this means training on 140B+ tokens. For a 70B model, approximately 1.4T tokens.
Detailed Cost Estimates by Model Size
| Model Size | Training Tokens | H100 GPU-Hours | Cost (H100 @ $3.49/hr) | Cost (A100 @ $2.09/hr) |
|---|---|---|---|---|
| 1.3B | 26B | ~400 | $1,396 | $1,672 (800 hrs) |
| 7B | 140B | ~5,000 | $17,450 | $20,900 (10K hrs) |
| 13B | 260B | ~15,000 | $52,350 | $62,700 (30K hrs) |
| 70B | 1.4T | ~200,000 | $698,000 | $836,000 (400K hrs) |
These estimates assume efficient implementations with Model FLOP Utilization (MFU) of approximately 45-50%. Poorly optimized training code can reduce MFU to 20-30%, effectively doubling or tripling the cost. Investing in training efficiency engineering is the highest-leverage cost optimization available.
Beyond Compute: The Full Cost Stack
Raw GPU-hours are typically only 40-60% of the total project cost for serious AI training initiatives. Several additional cost categories must be included in a complete budget.
Data Acquisition and Preparation
For pre-training, assembling and cleaning a multi-trillion-token dataset is a massive undertaking. Web scraping infrastructure, deduplication pipelines, toxicity filtering, and quality scoring systems can cost $50,000-200,000 in engineering time for a mid-scale project. Many teams license curated datasets from providers like Common Crawl, RedPajama, or domain-specific sources, which carries its own costs.
Storage and Data Transfer
A pre-training dataset for a 7B model typically occupies 500GB-2TB in tokenized format. High-performance NVMe storage on GPU cloud providers costs $0.10-0.25/GB/month. For a multi-week training run with 2TB of data, storage costs add approximately $200-500. Data transfer fees between cloud providers or regions can add another $100-500 depending on volume and provider.
Evaluation and Iteration
Training a model once is rarely sufficient. Hyperparameter sweeps, learning rate experiments, architecture modifications, and evaluation runs typically consume 20-40% of the total compute budget. Budget for at least 3-5 complete training iterations when planning a pre-training project.
Engineering Labor
The most frequently underestimated cost is human engineering time. A senior ML engineer commands $200,000-400,000 per year in total compensation. A 3-month pre-training project requires at minimum 2-3 dedicated engineers for infrastructure, training optimization, and evaluation. This labor component alone can cost $150,000-300,000 — often exceeding the raw compute bill for mid-scale projects.

Cost Optimization Strategies
Several proven strategies can significantly reduce your total training cost without sacrificing model quality:
- Maximize Model FLOP Utilization (MFU): This is the single most impactful optimization. Using optimized kernels (FlashAttention-2, fused operations), efficient data loaders, and proper parallelism strategies can increase MFU from 30% to 50%+, reducing training time by 40% or more.
- Use mixed-precision training: BF16 training on A100 or FP8 training on H100 roughly doubles throughput compared to FP32, cutting compute costs in half.
- Spot instances for experimentation: Run hyperparameter sweeps and architecture experiments on spot instances at 40-70% discounts. Reserve on-demand instances only for the final production training run.
- Right-size your GPU: Not every task needs an H100. Fine-tuning with LoRA on an RTX 4090 ($0.39/hr) is 9x cheaper per hour than an H100. Match the GPU to the workload complexity.
- Leverage pre-trained checkpoints: Starting from an existing open-source checkpoint (Llama 3, Mistral, Qwen) and doing continued pre-training on domain data is 5-10x cheaper than training from scratch.
For a detailed comparison of GPU hourly rates across providers, visit our Provider Directory. Use the comparison tool to evaluate specific GPU configurations, or explore GPU type specifications to match hardware to your training requirements.
Real-World Budget Examples
Scenario 1: AI Startup Building a Domain-Specific Chatbot
Approach: Fine-tune Llama 3 8B with LoRA on 100K curated examples.
Hardware: 1x A100 80GB on Lambda Labs.
Compute Cost: ~$45 (20 GPU-hours × $2.09/hr).
Data Preparation: ~$5,000 (2 weeks of annotation and cleaning).
Total Project Cost: ~$8,000 (including engineering time).
Scenario 2: Series A Startup Training a 7B Medical LLM
Approach: Continued pre-training on 50B tokens of medical literature, followed by SFT.
Hardware: 32x H100 SXM5 on CoreWeave (4-node cluster).
Compute Cost: ~$18,000 (5,000 GPU-hours × $3.49/hr).
Data Licensing: ~$25,000 (PubMed, clinical trial databases).
Total Project Cost: ~$120,000 (including 3 engineers for 6 weeks).
Scenario 3: Well-Funded Lab Pre-Training a 70B Foundation Model
Approach: Train from scratch on 2T tokens with custom architecture.
Hardware: 512x H100 SXM5 on CoreWeave/Voltage Park (reserved 3-month contract).
Compute Cost: ~$600,000-800,000 (200K GPU-hours × $3.09/hr reserved).
Infrastructure Engineering: ~$300,000 (team of 5 for 4 months).
Total Project Cost: ~$1.2-1.8 million.
Build vs. Buy: When Self-Training Beats API Access
One of the most fundamental decisions facing AI teams is whether to train a custom model or consume intelligence via API from providers like OpenAI, Anthropic, or Google. The economics are nuanced and depend on four critical variables.
First, volume matters enormously. If your application processes fewer than 500,000 tokens per day, API access is almost always cheaper. At 1 million tokens per day using GPT-4-class models, API costs run approximately $30-60 per day ($900-1,800/month). A self-hosted fine-tuned 7B model on a single A100 costs approximately $50/day ($1,500/month) for continuous operation — roughly comparable. But at 10 million tokens per day, the API bill balloons to $9,000-18,000/month while the self-hosted cost remains $1,500/month. At scale, self-hosting delivers 5-12x cost savings.
Second, customization requirements drive the decision. API models are general-purpose. If your use case requires deep domain expertise (medical diagnosis, legal analysis, financial compliance), a fine-tuned model will significantly outperform a general API at the specific task. The upfront AI training cost of fine-tuning ($50-2,000) is typically recovered within the first month of production usage through improved output quality and reduced need for expensive prompt engineering.
Third, latency and privacy are often deciding factors. Self-hosted models eliminate the 200-500ms network round-trip to a third-party API and ensure that sensitive data never leaves your infrastructure. For applications in healthcare, finance, and government, data sovereignty requirements make self-hosting mandatory regardless of cost considerations.
Fourth, model control and reliability. When you depend on a third-party API, you are subject to their rate limits, pricing changes, and model deprecation schedules. OpenAI has retired models with as little as six months’ notice, forcing dependent applications to migrate. Self-hosted models give you complete control over versioning, availability, and performance characteristics.
Frequently Asked Questions
How much does it cost to fine-tune ChatGPT or Llama 3?
Fine-tuning Llama 3 8B with LoRA on a curated dataset of 50,000 examples costs approximately $15-50 in GPU compute on a specialized cloud provider. Full-weight fine-tuning of the same model costs $500-1,500. OpenAI’s GPT fine-tuning API charges per token processed, with typical costs ranging from $25-200 for small to medium datasets. For enterprise-scale fine-tuning of 70B+ parameter models, expect costs of $2,000-10,000 in compute alone.
Is it cheaper to train my own AI model or use an API like OpenAI?
For low-volume usage (under 1 million tokens per day), API services like OpenAI or Anthropic are almost always cheaper than training and hosting your own model. For high-volume production usage (over 10 million tokens per day), self-hosted models become dramatically cheaper — often 5-20x less expensive per token. The break-even point depends on your daily token volume, latency requirements, and customization needs. Most startups reach the self-hosting break-even between 2-5 million tokens per day.
What is the cheapest way to train an AI model in 2026?
The cheapest approach is to fine-tune an existing open-source model (like Llama 3 or Mistral) using LoRA on an RTX 4090 via Vast.ai or RunPod Community Cloud, costing as little as $5-20 for a complete fine-tuning run. For pre-training, using spot H100 instances during off-peak hours on FluidStack or RunPod can reduce costs by 40-60% compared to on-demand pricing on hyperscalers.
How do I estimate GPU hours needed for my training project?
A rough formula for estimating GPU hours for pre-training: (6 × model_parameters × training_tokens) / (GPU_FLOPS × utilization_rate × 3600). For an H100 with ~1,000 TFLOPS (FP8) and 45% MFU, training a 7B model on 140B tokens requires approximately 5,000 GPU-hours. For fine-tuning with LoRA, the calculation is simpler: expect 2-20 GPU-hours depending on dataset size and model parameters. We recommend running a short benchmark (100 steps) to measure your actual throughput before committing to a full training run.
Get personalised, no-commitment quotes from top AI infrastructure providers in under 2 minutes.


