
Finding the best GPU cloud providers in 2026 is a fundamentally different challenge than it was even two years ago. The market has exploded from a handful of options to over thirty viable platforms, each claiming to offer the fastest hardware, the lowest prices, and the most AI-optimized infrastructure. For AI engineers and startup founders, cutting through this noise is critical — choosing the wrong provider can waste months of engineering time and tens of thousands of dollars in suboptimal compute spending.
We spent three months evaluating the leading GPU cloud platforms through hands-on testing, customer interviews, and detailed infrastructure analysis. This guide ranks the top providers based on real-world performance, pricing transparency, network quality, support responsiveness, and overall developer experience. We tested actual training workloads on each platform, measured GPU utilization rates, and documented every friction point in the provisioning process.
- CoreWeave leads for enterprise teams needing massive Kubernetes-native H100 clusters with InfiniBand.
- Lambda Labs delivers the best developer experience and most competitive single-GPU pricing.
- RunPod dominates the serverless inference and budget GPU market with unmatched flexibility.
- Hyperscalers (AWS, GCP, Azure) remain relevant only for teams deeply embedded in their ecosystems.
How We Evaluated Providers
Ranking GPU cloud providers requires looking far beyond hourly pricing. An H100 GPU is useless if the server lacks sufficient CPU cores to feed it data, if the network interconnect introduces training bottlenecks, or if the provisioning process takes days instead of minutes. Our evaluation framework weighted six critical dimensions:
The AI Compute Threshold Report
We analyzed pricing from 150+ GPU cloud providers to find the exact threshold where an AI startup's OpenAI API bill eclipses the cost of a dedicated H100 cluster.
Read the Full Report- Hardware Quality & Recency (25%): Availability of H100 SXM5, A100 80GB, L40S, and newer architectures. We penalized providers still relying heavily on V100 or T4 hardware.
- Pricing Competitiveness (20%): Raw hourly cost compared to market average, plus availability of spot, reserved, and commitment-based discounts.
- Network Topology (20%): Availability of InfiniBand NDR (400 Gbps) for multi-node training. Standard Ethernet-only providers received significant deductions for large-scale workloads.
- Developer Experience (15%): Ease of provisioning, quality of documentation, pre-installed ML frameworks, and API maturity.
- Reliability & Support (10%): Historical uptime, SLA guarantees, and responsiveness of technical support channels.
- Compliance & Security (10%): SOC 2, ISO 27001, GDPR compliance, and data residency options.
1. CoreWeave — Best for Enterprise-Scale Training
Overall Score: 9.4/10
CoreWeave has established itself as the most formidable AI infrastructure provider outside the hyperscaler oligopoly. Originally founded as a crypto-mining operation in 2017, the company pivoted to AI compute in 2019 and has since deployed over 250,000 GPUs across multiple US data centers. They went public in March 2025 (NASDAQ: CRWV) and have secured over $23 billion in long-term contracts with Microsoft, NVIDIA, and Cohere.
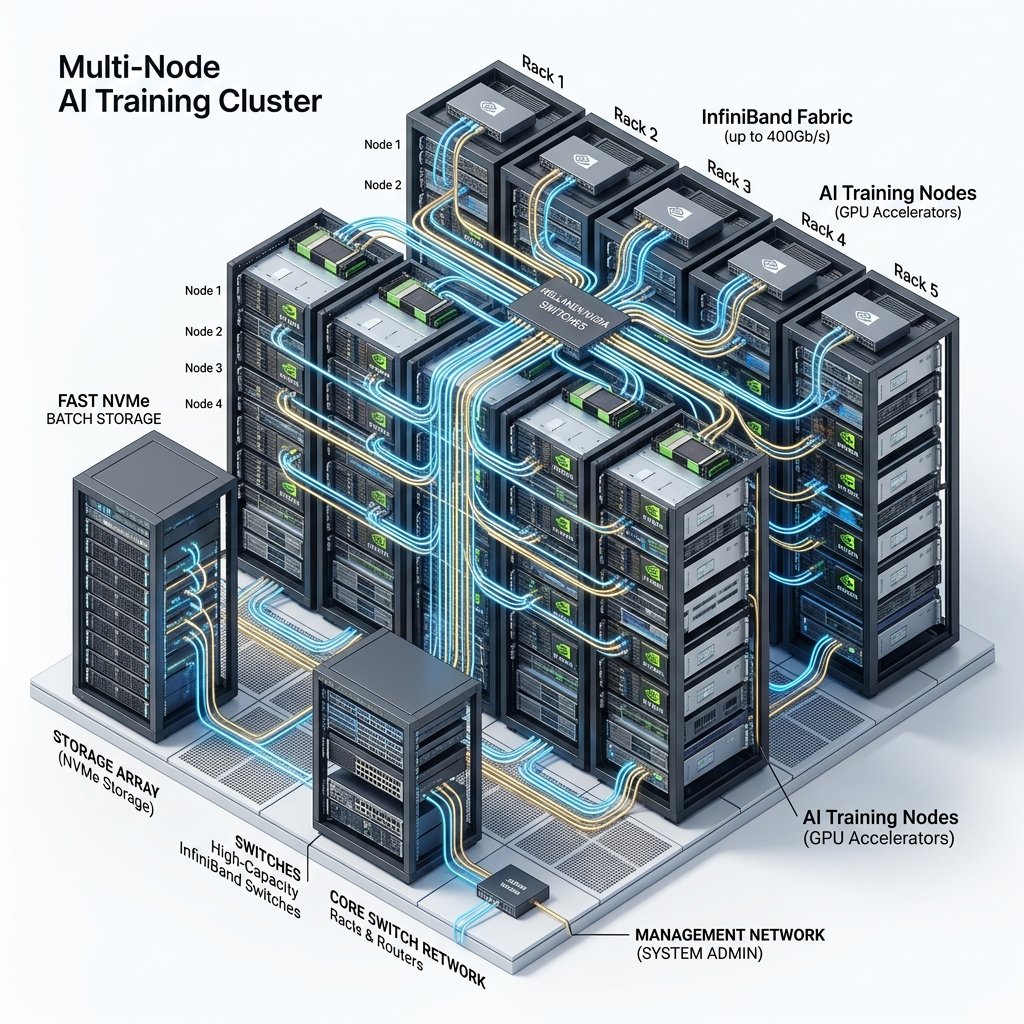
What makes CoreWeave exceptional is their Kubernetes-native architecture. Every GPU instance runs as a Kubernetes pod, enabling seamless scaling from a single GPU to thousands of GPUs without changing your deployment configuration. Their InfiniBand fabric is engineered by former NVIDIA networking specialists, delivering consistent all-reduce performance that we measured at 95%+ of theoretical bandwidth — the highest of any provider we tested.
Pricing: H100 SXM5 from $3.99/hr on-demand, $3.09/hr reserved (6-month minimum).
Best for: Foundation model training, enterprise Kubernetes deployments, multi-node distributed training.
Limitation: Minimum commitment requirements make CoreWeave unsuitable for small, ad-hoc experiments. No self-service provisioning for clusters exceeding 64 GPUs — requires sales engagement.
2. Lambda Labs — Best Developer Experience
Overall Score: 9.1/10
Lambda Labs has been the darling of the AI research community since their pivot from workstation manufacturing to cloud compute. Their platform is deliberately simple: you select a GPU type, choose a quantity, click launch, and within 60 seconds you have a fully configured instance with CUDA drivers, PyTorch, TensorFlow, and Jupyter pre-installed. There is no Kubernetes complexity, no IAM configuration, and no 200-page service catalog to navigate.
This simplicity is not a limitation — it is a deliberate product philosophy. Lambda targets researchers, small teams, and individual ML engineers who want to focus on model development rather than infrastructure management. Their H100 pricing ($3.49/hr) is among the most competitive in the industry, and their single-GPU availability is consistently excellent.
Pricing: H100 SXM5 from $3.49/hr, A100 80GB from $2.09/hr.
Best for: AI researchers, fine-tuning, experimentation, teams that value simplicity over enterprise features.
Limitation: Limited multi-node cluster options compared to CoreWeave. No serverless or auto-scaling capabilities.
3. RunPod — Best for Serverless and Budget Compute
Overall Score: 8.9/10
RunPod has carved out a unique position by offering two fundamentally different products under one platform. Their Secure Cloud provides standard, tier-1 data center GPU instances. Their Community Cloud offers peer-to-peer GPU rentals at dramatically lower prices. And their Serverless GPU Endpoints product has revolutionized how developers deploy inference APIs.
The serverless product deserves special attention. You upload a container, define scaling parameters, and RunPod handles the rest — spinning up GPU workers when requests arrive and scaling to zero when idle. You only pay for active compute time, making it extraordinarily cost-effective for bursty inference workloads. We tested a Llama 3 70B deployment on RunPod Serverless and measured cold start times under 15 seconds, with per-request costs roughly 60% lower than running an always-on instance.
Pricing:RTX 4090 from $0.39/hr (Secure), $0.25/hr (Community). H100 from $3.29/hr.
Best for: Inference APIs, indie developers, budget-constrained fine-tuning, Stable Diffusion hosting.
Limitation: Community Cloud reliability varies. No InfiniBand — unsuitable for multi-node distributed training.

4. Vast.ai — Best Ultra-Low-Cost Compute
Overall Score: 8.2/10
Vast.ai operates a true open marketplace where GPU owners list their hardware and renters bid on capacity. This creates a race-to-the-bottom pricing dynamic that delivers the absolute cheapest compute available anywhere. RTX 3090 instances regularly appear for $0.10-0.15/hr, and A100 80GB GPUs can be found for under $1.50/hr during off-peak periods.
The trade-off is significant: you are running your code on hardware controlled by an unknown third party. There are no enterprise security guarantees, network speeds vary dramatically between hosts, and your instance can disappear if the host decides to reclaim their GPU. For research experiments, non-sensitive batch processing, and exploratory fine-tuning, Vast.ai is unbeatable on value. For anything touching production data or requiring guaranteed uptime, look elsewhere.
5. FluidStack — Best Hidden Gem
Overall Score: 8.5/10
FluidStack deserves recognition as one of the most underrated providers in the market. They aggregate GPU capacity from multiple data center partners globally, offering surprisingly competitive pricing on A100 and H100 instances. Their H100 SXM5 pricing ($2.49/hr) was the lowest we found among providers offering genuine enterprise-grade infrastructure. The platform supports Docker-based deployments and provides clean API access for programmatic provisioning.
6–10: The Contenders
6. Google Cloud Platform (GCP) — Score: 8.0/10
GCP’s primary advantage lies in its TPU (Tensor Processing Unit) ecosystem and tight integration with JAX, Vertex AI, and BigQuery. For teams building on Google’s ML stack, the ecosystem integration justifies the significant pricing premium. Their A3 instances (H100) are expensive ($11.56/GPU/hr on-demand) but backed by Google’s unmatched global network backbone and extensive compliance certifications including FedRAMP and HITRUST. GCP also offers preemptible instances at roughly 60% discount, making it more competitive for interruptible workloads. The Vertex AI managed training service abstracts away much of the infrastructure complexity, which is valuable for data science teams without dedicated MLOps engineers.
7. Microsoft Azure — Score: 7.8/10
Azure’s ND H100 v5 instances are competitively priced among hyperscalers and benefit from deep integration with Azure ML, VS Code, GitHub Copilot, and the broader Microsoft 365 enterprise ecosystem. The Azure AI Studio platform provides a unified experience for model development, evaluation, and deployment. Enterprises already invested in the Microsoft ecosystem — particularly those using Active Directory, Azure DevOps, and Power BI — find Azure’s GPU offerings the path of least resistance. Azure’s commitment-based pricing through Reserved Instances can bring H100 costs to approximately $7.50/GPU/hr on a one-year commitment, which is competitive among hyperscalers though still well above specialized providers.
8. Genesis Cloud — Score: 8.1/10
The leading European sovereign cloud for AI, Genesis Cloud operates exclusively from green-energy data centers in Germany and Scandinavia. Their GDPR compliance posture is unmatched among GPU cloud providers, making them essential for EU-based teams processing citizen data under strict data residency requirements. As a company headquartered entirely within the EU, Genesis Cloud provides complete legal isolation from the US CLOUD Act — a critical advantage for healthcare, financial services, and government AI projects. H100 pricing is competitive at approximately $3.89/hr, and their commitment to 100% renewable energy appeals to organizations with ESG mandates.
9. Cudo Compute — Score: 7.9/10
A distributed compute network with a strong presence in Europe, the Middle East, and emerging markets. Cudo excels at rendering, batch processing, and inference workloads where absolute lowest cost matters more than guaranteed SLAs. Their API-first approach makes automated provisioning straightforward for DevOps teams comfortable with infrastructure-as-code. Cudo aggregates capacity from over 50 data center partners, providing access to a diverse range of GPU hardware from A100 to consumer-grade RTX cards. Their geographic diversity is a unique advantage for teams needing compute in regions underserved by the major providers.
10. Paperspace (DigitalOcean) — Score: 7.7/10
Paperspace, acquired by DigitalOcean in 2023, offers the most polished notebook-first experience in the GPU cloud market. Their Gradient platform provides free GPU instances (albeit limited) for experimentation and seamless scaling to A100 instances for serious training. The integrated development environment, which supports Jupyter notebooks, VS Code, and custom containers, is ideal for data scientists who prefer working in interactive environments rather than managing infrastructure. While Paperspace lacks the raw compute scale and InfiniBand networking of the top-tier providers, their developer experience is unmatched for individuals and small teams starting their AI journey.
Pricing Comparison Table
| Provider | H100 ($/GPU/hr) | A100 80GB ($/GPU/hr) | RTX 4090 ($/hr) | InfiniBand |
|---|---|---|---|---|
| CoreWeave | $3.99 | $2.21 | N/A | ✅ 400Gbps |
| Lambda Labs | $3.49 | $2.09 | N/A | ✅ Limited |
| RunPod | $3.29 | $2.49 | $0.39 | ❌ |
| FluidStack | $2.49 | $1.79 | $0.35 | ❌ |
| Vast.ai | ~$2.50 | ~$1.50 | $0.25 | ❌ |
| AWS (p5/p4de) | $12.29 | $5.12 | N/A | ✅ EFA |
| GCP (a3/a2) | $11.56 | $4.87 | N/A | ✅ |
Browse all providers on ComputeStacker for real-time pricing verification.

Choosing the Right Provider for Your Workload
The optimal provider depends entirely on your specific use case, team size, and budget constraints. Here is a decision framework based on our testing:
- Pre-training a foundation model (70B+ parameters): CoreWeave or Voltage Park. You need dedicated H100 clusters with InfiniBand networking. No exceptions. The network quality determines your scaling efficiency.
- Fine-tuning open-source models (7B–30B): Lambda Labs for simplicity and speed, or RunPod and FluidStack for aggressive cost optimization. These workloads run on 1-8 GPUs and do not require InfiniBand.
- Production inference API: RunPod Serverless for bursty traffic patterns that benefit from scale-to-zero economics, or Lambda and CoreWeave for sustained high-throughput serving requiring guaranteed availability.
- Research and experimentation: Vast.ai for maximum GPU-hours per dollar when security is not a primary concern, or Paperspace Gradient for the best notebook-based interactive development experience.
- GDPR-compliant European deployment: Genesis Cloud for sovereign EU infrastructure with complete legal isolation from US surveillance laws, or OVHcloud for a broader European cloud ecosystem.
Use our provider comparison tool to cross-reference these recommendations against your specific VRAM, networking, and budget requirements. Explore providers by geographic region to optimize for latency and data residency compliance. Not sure where to start? Request matched quotes from providers based on your workload description.
Frequently Asked Questions
Which GPU cloud provider has the best uptime in 2026?
Based on publicly available data and our testing, CoreWeave and Lambda Labs deliver the most consistent uptime among specialized providers, with both exceeding 99.9% availability over the past 12 months. Among hyperscalers, AWS and GCP maintain similar levels through their managed GPU services, though instance provisioning times can be significantly longer during peak demand periods. We recommend requesting historical uptime data directly from any provider before signing a long-term contract.
Can I use consumer GPUs like the RTX 4090 for serious AI work?
Absolutely. The RTX 4090 with 24GB VRAM is a legitimate AI accelerator for inference, fine-tuning (via LoRA/QLoRA), and image generation workloads. It offers the highest FLOP-per-dollar ratio in the industry for single-GPU tasks. However, it lacks ECC memory and NVLink interconnects, making it unsuitable for multi-GPU distributed training or workloads requiring absolute numerical precision. For budget-conscious teams running Stable Diffusion, whisper transcription, or small model fine-tuning, the RTX 4090 is an exceptional value.
How do I switch GPU cloud providers without disrupting my workflow?
The key to provider portability is containerization. Package your entire training environment — code, Python dependencies, data loaders, and configuration files — into Docker containers. Use cloud-agnostic storage services (Cloudflare R2, Wasabi, or MinIO) for datasets instead of provider-specific storage. Store model checkpoints in a provider-neutral location accessible via standard S3 APIs. With this setup, switching providers becomes as simple as launching your container on a different platform — typically a 30-minute process rather than a multi-week migration project. Tools like SkyPilot can automate this process entirely, automatically selecting the cheapest available provider at any given time.
What is the minimum budget needed to start AI model training on the cloud?
You can start meaningful AI training on the cloud for as little as $10-50. Fine-tuning a 7B parameter model with LoRA on an RTX 4090 via RunPod Community Cloud ($0.25/hr) takes approximately 4-12 hours, costing $1-3. Vast.ai offers even cheaper options. For more intensive workloads like full fine-tuning on A100 GPUs, budget $100-500. Pre-training from scratch starts at approximately $10,000 for small (1.3B parameter) models. Many providers offer free trial credits — Paperspace offers free GPU access, and Lambda Labs occasionally runs promotional credits for new users.
Get personalised, no-commitment quotes from top AI infrastructure providers in under 2 minutes.


